ConcurrentHashMap底层原理
ConcurrentHashMap底层原理
jdk1.7是数组加链表,它在对象中保存了一个Segment数组。每个Segment元素类似于一个Hashtable;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可,不同的Segment可以并发put。而Segment的锁实现其实是ReentrantLock
jdk1.8则是采用了数组+链表/红黑树,他舍弃了Segment数组,用的是CAS + synchronized
1.7put流程:
为输入的Key做Hash运算,得到hash
通过hash,定位到对应的Segment对象(根据hash值的高4位(根据Segment数量决定是高几位,如果是32个Segment,就是高5位),找到对应Segment)
获取可重入锁
再次通过hash值,定位到Segment当中数组的具体位置
插入或覆盖HashEntry对象
释放锁
1.7get流程:
为输入的key做Hash运算,得到hash
通过hash,定位到对应的Segment对象
再次通过hash,定位到Segment当中数组的具体位置
为什么get不需要上锁?因为使用了大量的volatile(Node中的val和next是volatile)
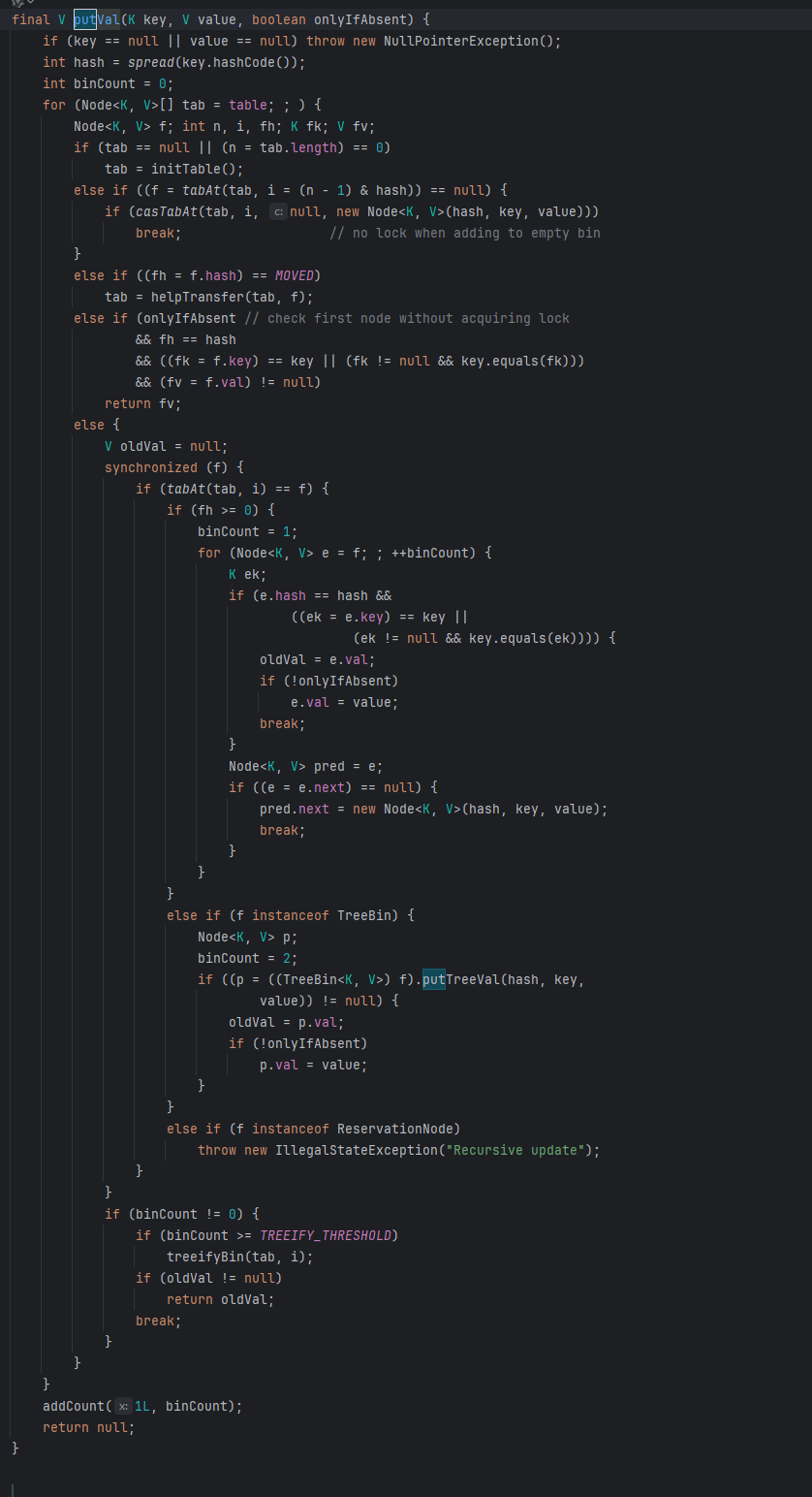
1.8put流程
检验key和value不能为null
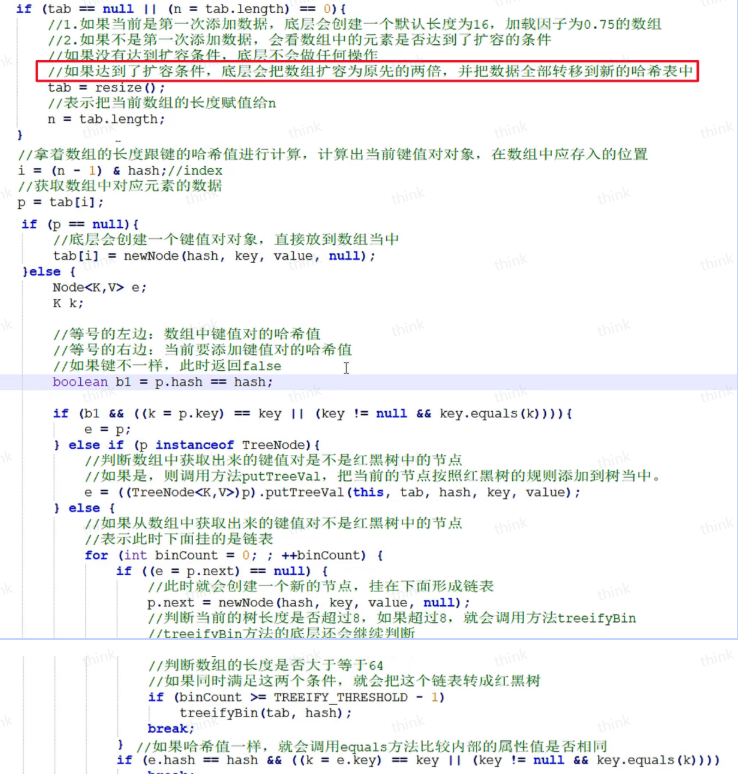
进入死循环
如果第一次添加元素,初始化table,使用CAS保证线程安全,然后重新进入循环
如果头节点为null,CAS将自己设置为头节点,成功则break,失败则重新进入循环
如果头节点是ForwardingNode,说明这个桶正在进行扩容,则帮忙进行扩容,然后重新进入循环
到了这里说明需要往桶下标的非头节点中添加元素,此时使用synchronized,锁对象是头节点
再次确认链表头节点有没有被移动
如果是链表,走链表put操作,如果有相同的key则更新,否则添加
如果是红黑树,走红黑树put操作,如果有相同的key则更新,否则添加
释放锁,判断是否需要树化,然后break
使用累加单元数组进行size累加,判断是否需要扩容
1.8get流程:无锁获取,因为Node[]和Node中的val和next有volatile
扩容
第一部分是构建一个 nextTable,它的容量是原来的两倍,这个操作是单线程完成的。
第二个部分是将原来 table 中的元素复制到 nextTable 中,主要是遍历复制的过程。遍历是从后往前遍历原table
得到当前遍历的数组位置 i,然后利用 tabAt 方法获得 i 位置的元素:
如果这个位置为空,就在原 table 中的 i 位置放入 forwardNode 节点,这个也是触发并发扩容的关键;
如果这个位置是 Node 节点(fh>=0),并且是链表的头节点,就把这个链表分裂成两个链表,把它们分别放在 nextTable 的 i 和 i+n 的位置上(桶下标不变的留在原地,变的放到 i + n 处);处理完后头节点变成forwardNode(如果是链表,则复制值创建新节点对象扩容,如果是一个节点,则挪动元素扩容)
如果这个位置是 TreeBin 节点(fh<0),也做一个反序处理,并且判断是否需要 untreefi,把处理的结果分别放在 nextTable 的 i 和 i+n 的位置上;处理完后头节点变成forwardNode
遍历所有的节点,就完成复制工作,这时让 nextTable 作为新的 table,并且更新 sizeCtl 为新容量的 0.75 倍 ,完成扩容。
扩容会把正在扩容的头结点设置成一个特殊结点,然后从get,put的角度说
扩容时有其余线程来get:如果头节点是forwardNode,那么就去新table中get,否则,在原table中查询,又因为迁移链表时是深拷贝扩容,所以get能查找到对应元素,不会出现并发问题
扩容时有其余线程来put:
如果要put的桶下标还不在扩容中,直接put
如果put的桶下标正在扩容中,只能阻塞
如果put的桶下标是forwarding,此时不能往新table中put,因为此时新table还没扩容完成,put可能产生并发问题,此时会去协助扩容