ConcurrentHashMap底层原理
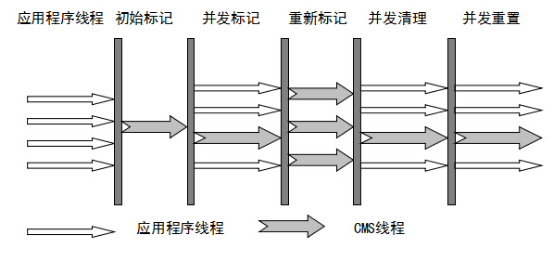
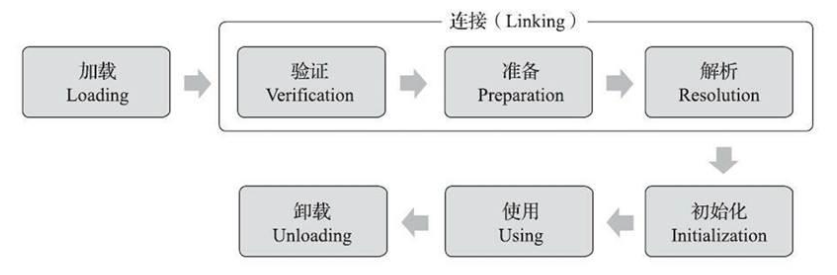
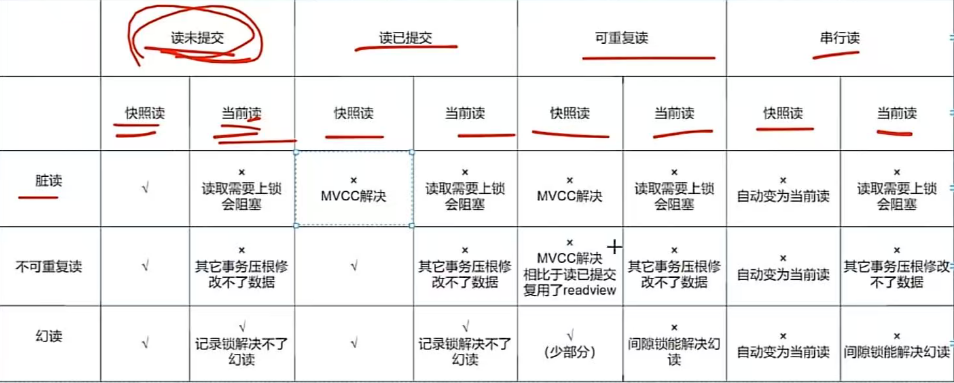
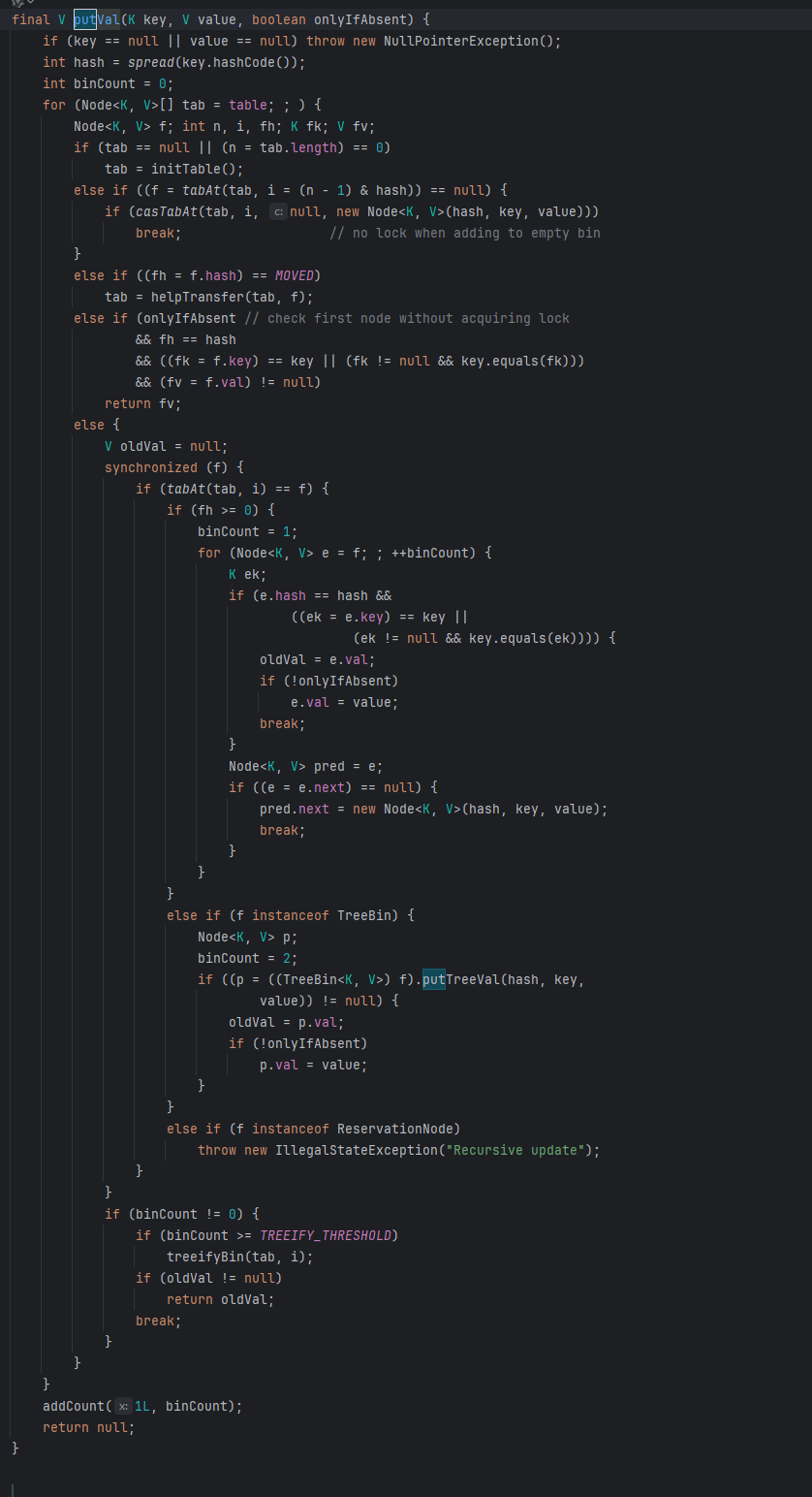
ConcurrentHashMap底层原理 jdk1.7是数组加链表,它在对象中保存了一个Segment数组。每个Segment元素类似于一个Hashtable;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可,不同的Segment可以并发put。而Segment的锁实现其实是ReentrantLock jdk1.8则是采用了数组+链表/红黑树,他舍弃了Segment数组,用的是CAS +...
SpringIOC
什么是 IoC? IoC (Inversion of Control )即控制反转/反转控制。它是一种思想不是一个技术实现。描述的是:Java 开发领域对象的创建以及管理的问题。 例如:现有类 A 依赖于类 B 传统的开发方式 :往往是在类 A 中手动通过 new 关键字来 new 一个 B 的对象出来 使用 IoC 思想的开发方式 :不通过 new 关键字来创建对象,而是通过 IoC 容器(Spring 框架) 来帮助我们实例化对象。我们需要哪个对象,直接从 IoC 容器里面去取即可。 从以上两种开发方式的对比来看:我们 “丧失了一个权力” (创建、管理对象的权力),从而也得到了一个好处(不用再考虑对象的创建、管理等一系列的事情) 为什么叫控制反转? 控制 :指的是对象创建(实例化、管理)的权力 反转 :控制权交给外部环境(IoC 容器) IoC 解决了什么问题? IoC 的思想就是两方之间不互相依赖,由第三方容器来管理相关资源。这样有什么好处呢? 对象之间的耦合度或者说依赖程度降低; 资源变的容易管理;比如你用 Spring...
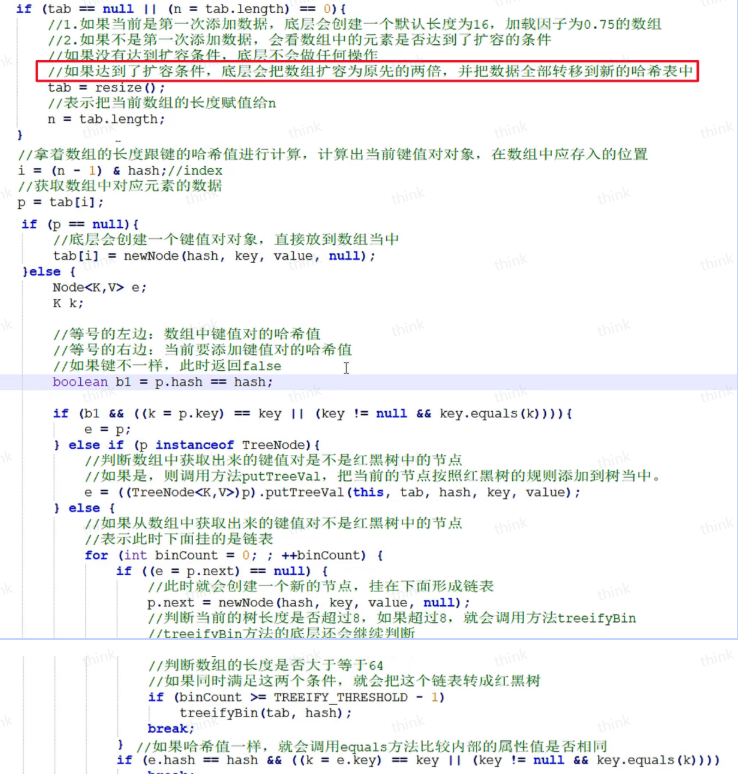
HashMap
HashMap JDK 7 中 HashMap 的数据结构是数组+链表。 JDK 8 中 HashMap 的数据结构是数组+链表+红黑树。 它在链表长度大于8且数组长度大于64时候会把链表转换成红黑树 HashMap 的初始容量是 16,随着元素的不断添加,HashMap 就需要进行扩容,阈值是capacity * loadFactor,capacity 为容量,loadFactor 为负载因子,默认为 0.75。 扩容后的数组大小是原来的 2 倍,然后把原来的元素重新计算哈希值,放到新的数组中。 负载因子(load factor)是一个介于 0 和 1 之间的数值,用于衡量哈希表的填充程度。它表示哈希表中已存储的元素数量与哈希表容量之间的比例。 负载因子过高(接近 1)会导致哈希冲突增加,影响查找、插入和删除操作的效率。 负载因子过低(接近 0)会浪费内存,因为哈希表中有大量未使用的空间。 HashMap 的put过程: 1.他会先对key计算扰动hash,通过key.hashCode() ^ (key.hashCode() >>>...

Volatile原理
Volatile原理
MySQL 联合索引的最左匹配原则
MySQL 联合索引的最左匹配原则 执行计划基础知识 possible_keys:可能用到的索引 key:实际用到的索引 type: ref:当通过普通的二级索引列与常量进行等值匹配的方式 询某个表时 const:当我们根据主键或者唯一得二级索引列与常数进行等值匹配时,对单表的访问方法就是 const range:如果使用索引获取某些单点扫描区间的记录。 index:当可以使用覆盖 ,但需要扫描全部的索引记录时。 Extra: Using index 索引覆盖 Using Where 当某个搜索条件需要在 server 层进行判断时 Using index for skip scan 跳跃扫描 Using index condtion 索引下推 最左匹配原则 最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。 比如有联合索引 [a、b、c],where 过滤条件中哪些排列组合可以用到索引?(比如这种:where a=xxx b=xxx and c=xxx) 以下排列组合都会走索引:...
redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性) 在项目中,我们主要通过 Redisson 的读写锁机制 来保证数据的强一致性。 当执行读取操作时,我们会加上读锁(共享锁),这样可以做到: 读读不互斥; 读写互斥。 而在更新数据时,我们会加上写锁(排他锁),此时写写、读写都互斥。 这样可以确保在写入数据库的同时,其他线程无法读取缓存数据,从而避免出现脏读或不一致的情况。 这里需要注意的一点是:读写方法必须使用同一把锁,才能真正保证互斥关系成立。 除了使用分布式锁,我们也考虑过使用 “延迟双删”策略 来实现最终一致性。 具体做法是: 先删除缓存; 再更新数据库; 最后延时一段时间后,再删除一次缓存。 不过,延迟的时间点很难精确把握。在延时窗口内仍可能出现脏数据问题,无法满足强一致性场景,因此我们最终没有采用这种方式。 在我最近做的项目中(例如简历中提到的 xxxx 功能), 系统对数据一致性的实时性要求没有那么高,可以接受一定的同步延时。 因此我们采用了 阿里巴巴的 Canal 组件 来实现最终一致性的数据同步。 Canal...
Redis分布式锁redisson看门狗机制
Redis分布式锁方案 使用 Redis 的 SET key value NX EX实现分布式锁时,主要问题是锁过期时间不好设置:如果设置过短,业务未完成锁就过期;设置过长,会降低系统并发度。为此可以使用 Redisson 封装的分布式锁,它内部通过「看门狗机制」自动续期锁(默认锁 30 秒,每 10 秒续期一次),同时通过 Lua 脚本保证加解锁的原子性,从而确保分布式环境下的并发安全。 Redisson分布式锁自动续约机制(看门狗) 线程1尝试tryLock锁未指定锁的过期时间 获取成功后会自动启动看门狗机制 初始加锁: 当调用 lock() 时,Redisson 会通过 Lua 脚本向 Redis 发送加锁命令,设置锁的初始过期时间为 LockWatchdogTimeout(默认 30 秒)。 锁的数据结构为 Hash,键为锁名称,field 为线程 ID,value 为重入次数。 启动定时任务: 加锁成功后,Redisson 会启动一个后台定时任务(通过 Netty 的 HashedWheelTimer 实现),每隔 10 秒执行一次。 ...
LeetCode Hot 100 - 24. 两两交换链表中的节点
LeetCode 24. 两两交换链表中的节点 题目大意 给定一个单链表,需要将链表中的节点按顺序两两交换,并返回交换后新的链表头节点。禁止只交换节点的数值,必须真实地调整指针。当链表长度为奇数时,最后一个节点保持原状。 示例 输入:head = [1,2,3,4] 输出:[2,1,4,3] 当输入为 head = [1,2,3] 时,结果应为 [2,1,3],因为第三个节点无法参与交换。 代码实现 1234567891011121314151617181920212223242526272829303132/** * Definition for singly-linked list. * public class ListNode { * int val; * ListNode next; * ListNode() {} * ListNode(int val) { this.val = val; } * ListNode(int val, ListNode next)...
Redis的数据过期淘汰策略
Redis 的数据过期策略 Redis 采用 「惰性删除 + 定期删除」 两种策略相结合的方式,在 CPU 性能开销 与 内存占用 之间取得平衡。 一、惰性删除(Lazy Expiration) 当客户端访问或修改某个键时,Redis 会在操作前调用 expireIfNeeded() 函数检查该键是否已过期: 若已过期: Redis 会立即删除该键,然后向客户端返回 null。 删除方式由配置项 lazyfree-lazy-expire 决定: 若开启(yes),则采用 异步删除; 若关闭(no),则采用 同步删除。 若未过期: 直接返回该键对应的正常值,不做任何额外处理。 这种方式的优点是 删除时机精准、不会浪费 CPU 时间; 缺点是:若某些过期键一直未被访问,就无法被清除,会长期占用内存。 二、定期删除(Active Expiration Cycle) 为了解决惰性删除的不足,Redis 还会周期性地扫描部分键空间,清除已过期的数据。 1. 检查频率 Redis 默认每秒执行 10 次过期扫描,这一频率由配置文件 redis.conf 中的参数 hz...
缓存穿透,雪崩,击穿
缓存穿透 缓存穿透指的是:一个缓存和数据库中都不存在的数据,由于数据库无法写入缓存,导致频繁请求直接打到数据库,从而造成数据库压力过大甚至被“打穿”。 常见的解决方法包括:缓存空值 或 布隆过滤器。 布隆过滤器由一个全 0 的位图数组和 n 个哈希函数组成。当一个数据在请求缓存前,会先经过布隆过滤器。过滤器会通过 n 个哈希函数计算出 n 个哈希值,再分别对数组长度取模,并将对应的数组下标置为 1。 查询时,只需要查看位图数组中这 n 个位置是否全部为 1: 若存在某个位为 0,则说明该数据一定不存在于数据库中; 若全部为 1,则说明该数据可能存在,但不一定真的存在,因为可能出现哈希碰撞。 因此,布隆过滤器判断“存在”时并不能保证数据真的存在,但判断“不存在”时一定准确。 缓存雪崩 缓存雪崩指的是:大量的缓存 Key 在同一时间失效,或者 Redis 服务器宕机,导致所有请求同时打到数据库,造成数据库瞬时压力过大,甚至宕机的情况。 解决方法: 为缓存设置 固定过期时间 + 随机过期时间,让不同 Key 的过期时间错开,避免在同一时间集中失效。 ...